資料分析
2008年Jeff Hamerbatcher與DJ Patil circa分別在FACEBOOK、Linkedin領導全球第一支資料科學團隊,全球首次有「資料科學」的概念出現。至此資料科學越來越被廣泛流行,並應用到公衛、市場、金融、社會等各個領域。
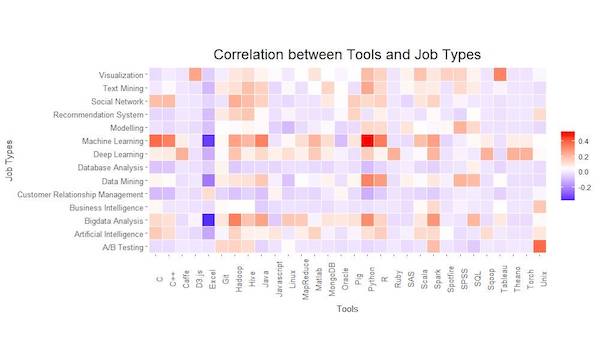
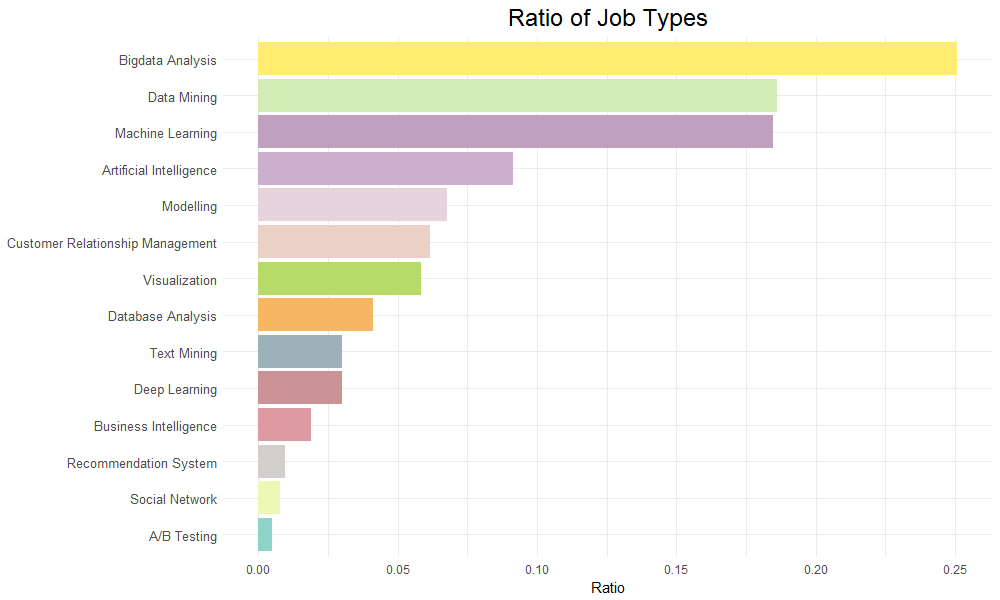
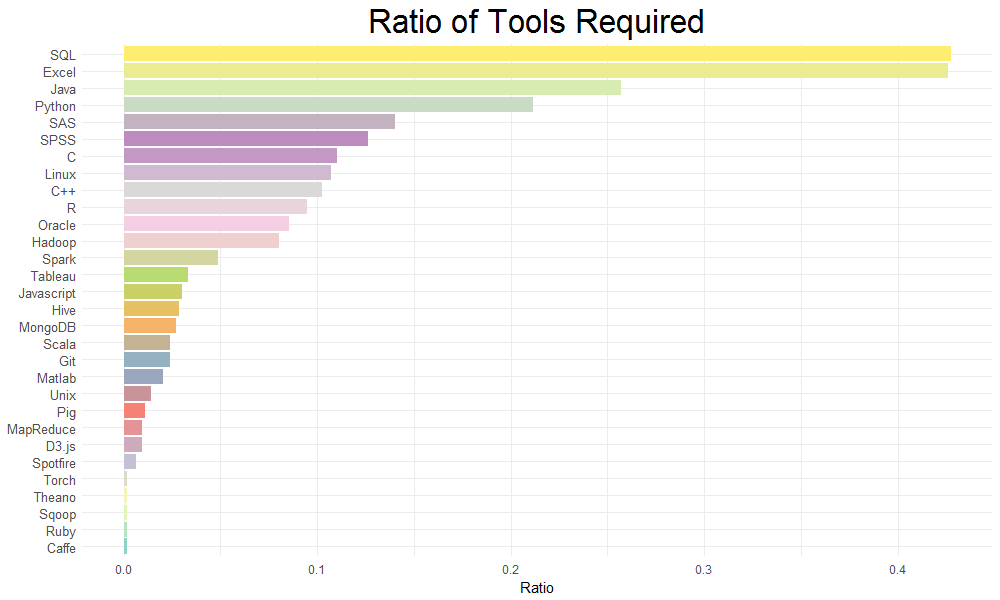
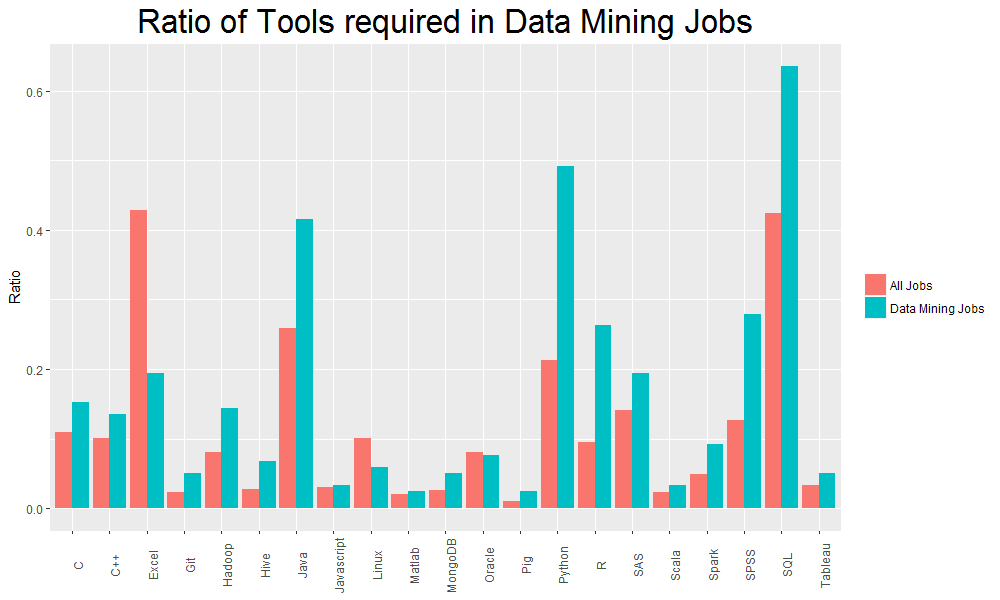
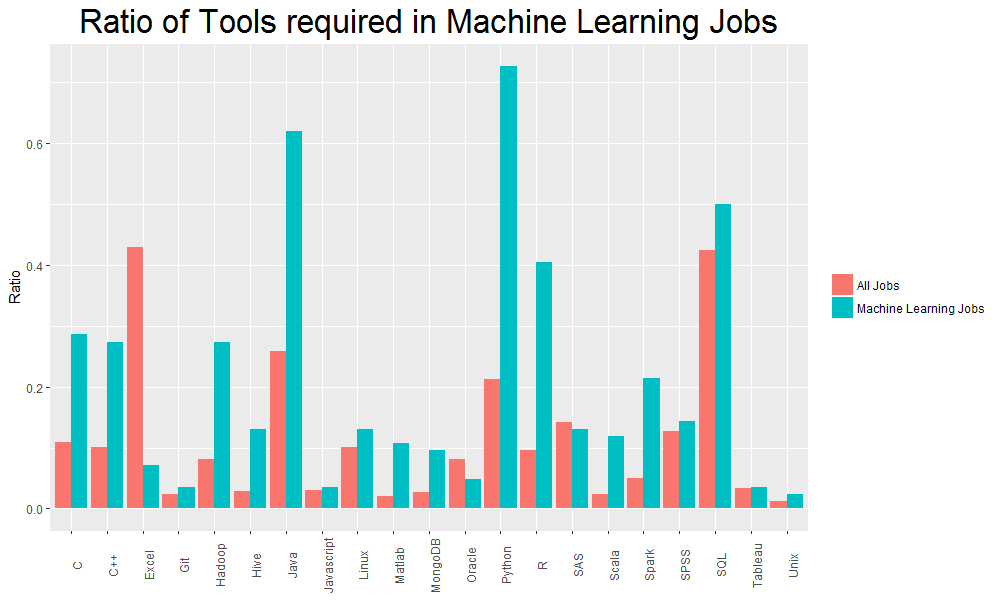
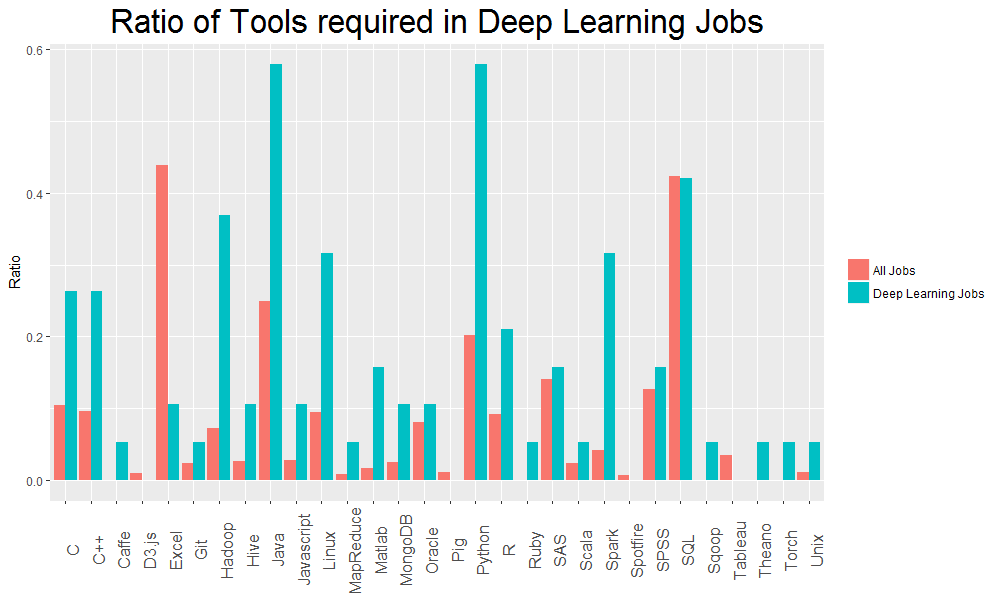
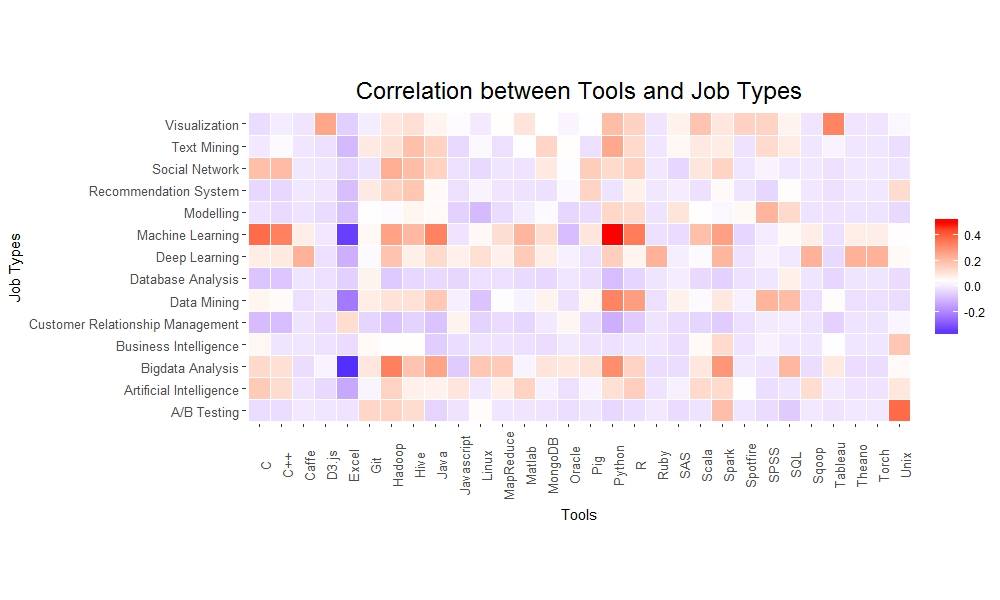
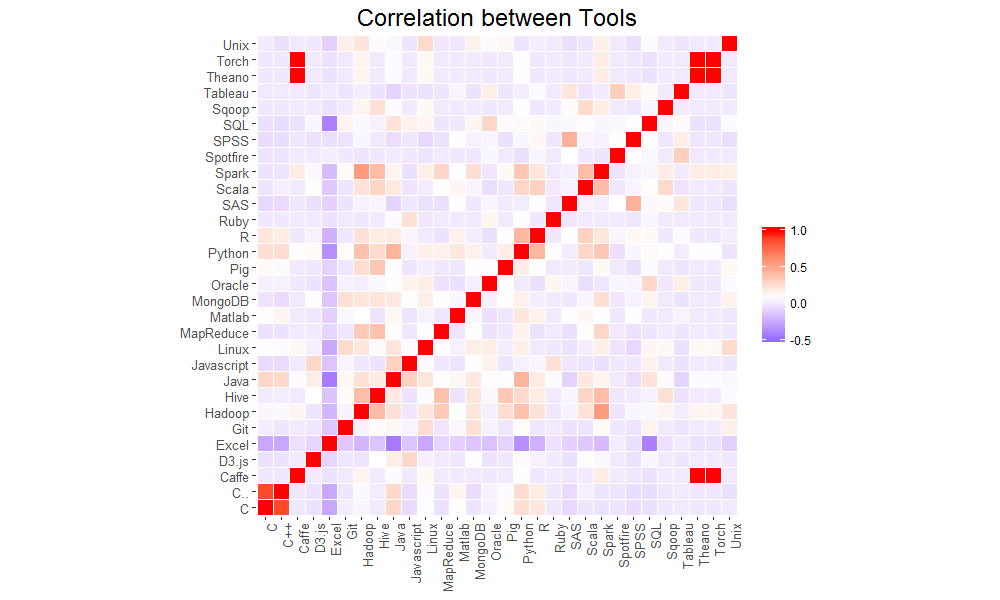
在台灣也有許多公司提供做資料科學的工作機會。因此本團隊以「資料科學」的關鍵字搜尋104求職網的資料,用R爬下2000多筆資料,並用程式、資料科學概念等關鍵字篩出所餘600筆資料。當中處理了詞彙相似與縮寫、C和R出現頻率等問題,再針對關鍵字於該筆工作資訊出現頻率做判斷與分析,得出我們的分析結果。
文章列表
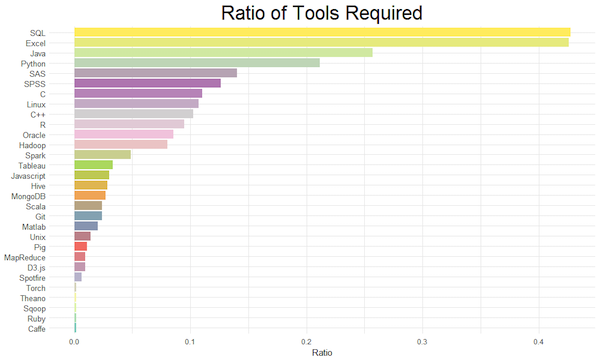
最流行的工具與資料科學領域

工具於資料科學領域裡的出現頻率